# Druid数据源连接池
# 概述
Durid是阿里巴巴开源的数据库连接池项目,其性能优越、内置强大的监控功能,监控特性不影响性能,能防SQL注入,并且还支持通过filter的机制进行扩展。
本章节主要讲解如何通过配置使用Druid的特性。
# 连接池配置属性列表
springboot中druid的配置示例如下:
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
url: jdbc:mysql://114.242.246.250:xxxx/demo?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8
username: root
password: xxxx
driver-class-name: com.mysql.jdbc.Driver
initial-size: 5 #初始化时建立物理连接的个数
max-active: 20 #最大连接池数量 maxIdle已经不再使用
min-idle: 5 #最小连接池数量
max-wait: 60000
pool-prepared-statements: false # 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭
max-pool-prepared-statement-per-connection-size: 200 #当值大于0时poolPreparedStatements会自动修改为true
validation-query: select 'x' #用来检测连接是否有效的sql
#申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
validationQueryTimeout:
test-on-borrow: false #申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-return: false #归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-while-idle: true
time-between-eviction-runs-millis: 60000 #既作为检测的间隔时间又作为testWhileIdel执行的依据
min-evictable-idle-time-millis: 300000 #销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接
具体参数请根据项目实际情况进行配置, 在上面的配置中,通常你需要配置url、username、password、driver-class-name这四项。
配置详解如下:
| 名称 | 作用 | 作用 |
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this). 另外配置此属性至少在1.0.5版本中是不起作用的,强行设置name会出错。 | |
| url | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码 | |
| driverClassName | 根据url自动识别 | 连接池驱动类, |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxPoolPreparedStatement PerConnectionSize | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 | |
| validationQueryTimeout | 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| keepAlive | false (1.0.28) | 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。 |
| timeBetweenEvictionRunsMillis | 1分钟(1.0.14) | 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
| numTestsPerEvictionRun | 30分钟(1.0.14) | 不再使用,一个DruidDataSource只支持一个EvictionRun |
| minEvictableIdleTimeMillis | 连接保持空闲而不被驱逐的最小时间 | |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件(使用该方式开启的都是默认功能),常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
# 内置filter
| Filter类名 | 别名 |
|---|---|
| default | com.alibaba.druid.filter.stat.StatFilter |
| stat | com.alibaba.druid.filter.stat.StatFilter |
| mergeStat | com.alibaba.druid.filter.stat.MergeStatFilter |
| encoding | com.alibaba.druid.filter.encoding.EncodingConvertFilter |
| log4j | com.alibaba.druid.filter.logging.Log4jFilter |
| log4j2 | com.alibaba.druid.filter.logging.Log4j2Filter |
| slf4j | com.alibaba.druid.filter.logging.Slf4jLogFilter |
| commonlogging | com.alibaba.druid.filter.logging.CommonsLogFilter |
| wall | com.alibaba.druid.wall.WallFilter |
# 启用监控页面
druid支持多种监控功能,如果想查看druid的监控,需要进行如下配置:
spring:
datasource:
druid:
stat-view-servlet: # 监控的web展示页面 配置
enabled: true #默认为false,表示不使用StatViewServlet配置,就是属性名去短线
url-pattern: /druid/* #配置DruidStatViewServlet的访问地址。后台监控页面的访问地址
reset-enable: false #禁用HTML页面上的“重置”功能,会把所有监控的数据全部清空,一般不使用
login-username: admin #监控页面登录的用户名
login-password: 123456 #监控页面登录的密码
allow: 223.71.143.178 #白名单中需要添加访问浏览器的外网ip
监控的web展示页面配置完成后,在浏览器中输入/druid,访问druid的监控页面,然后输入配置文件中的用户名密码,就可以查看监控记录了。
登录页面:

Druid首页:

Druid数据源信息页面:
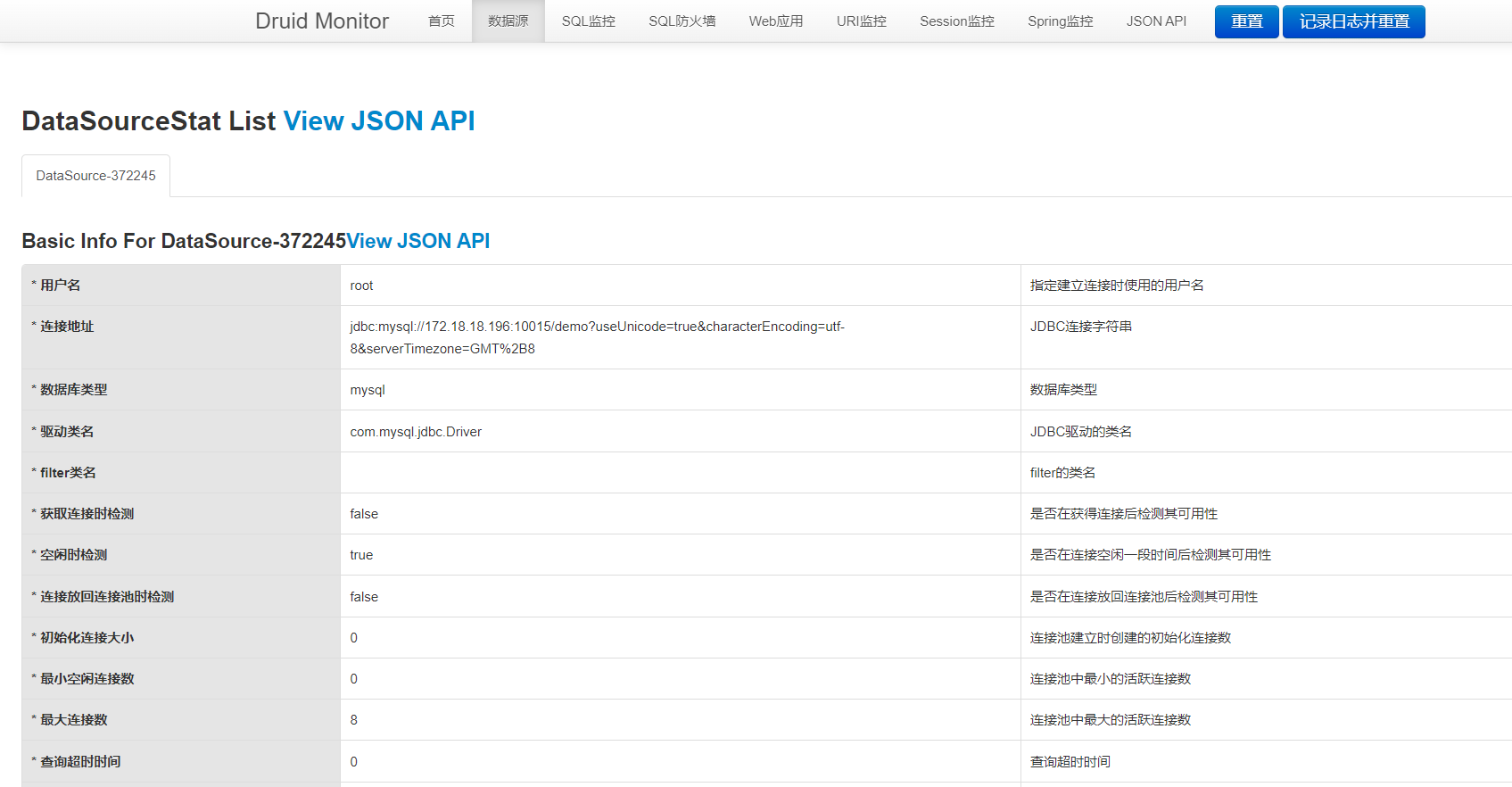
# SQL监控
Druid连接池的监控信息主要是通过StatFilter 采集的,采集的信息非常全面, StatFilter能采集到每个SQL的执行次数、执行时间、慢SQL查询、返回行数总和、更新行数总和、执行中次数和和最大并发执行时间区间分布等信息。
# SQL监控配置
spring:
datasource:
druid:
filter:
stat:
enabled: true #开启SQL监控
merge-sql: true #合并SQL
log-slow-sql: true #记录慢SQL
slow-sql-millis: 5000 #慢SQL定义时间
use-global-data-source-stat: true #合并多个数据源的监控
# 精简配置
spring:
datasource:
druid:
filters: stat #开启SQL监控
connection-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
通过精简模式开启的filter都是默认配置,如果需要对参数进行配置,还需要在connection-properties中进行配置,使用起来不太友好,因此在需要对filter进行复杂配置时不建议使用精简模式

# 合并SQL
当你程序中存在没有参数化的sql执行时,sql统计的效果会不好。比如:
select * from t where id = 1
select * from t where id = 2
select * from t where id = 3
在统计中,显示为3条sql,这不是我们希望要的效果。StatFilter提供合并的功能,能够将这3个SQL合并为如下的SQL
select * from t where id = ?
# 慢SQL配置
StatFilter属性slowSqlMillis用来配置SQL慢的标准,执行时间超过slowSqlMillis的就是慢。slowSqlMillis的缺省值为3000,也就是3秒。 开启慢SQL后,标红的记录就属于慢SQL。
# 合并多数据源的sql监控
spring:
datasource:
druid:
use-global-data-source-stat: true #合并多个数据源的监控
# SQL防火墙
WallFilter的功能是防御SQL注入攻击。它是基于SQL语法分析,理解其中的SQL语义,然后做处理的,智能,准确,误报率低。
# 效果图

# 防火墙配置
spring:
datasource:
druid:
filter:
wall:
db-type: #db类型
enabled: #启用,如果配置的是人大金仓数据库,此项需要关闭
log-violation: #对被认为是攻击的SQL进行LOG.error输出
provider-white-list: #白名单?
tenant-column: #占用列?
throw-exception: #对被认为是攻击的SQL抛出SQLExcepton
config:
##语句防火墙
#DQL
selelct-allow: #是否允许执行select语句
select-all-column-allow: #是否允许执行SELECT * FROM T这样的语句。如果设置为false,不允许执行select * from t,但select * from (select id, name from t) a。这个选项是防御程序通过调用select *获得数据表的结构信息。
select-except-check: #检测SELECT EXCEPT
select-intersect-check: #检测SELECT INTERSECT
select-minus-check: #检测SELECT MINUS
select-union-check: #检测SELECT UNION
select-into-allow: #是否允许执行 select into 语句
minus-allow: #是否允许SELECT * FROM A MINUS SELECT * FROM B这样的语句
select-into-outfile-allow: #SELECT ... INTO OUTFILE 是否允许,这个是mysql注入攻击的常见手段,缺省是禁止的
select-where-alway-true-check: #检查SELECT语句的WHERE子句是否是一个永真条件
select-having-alway-true-check: #检查SELECT语句的HAVING子句是否是一个永真条件
condition-and-alway-false-allow: #检查查询条件(WHERE/HAVING子句)中是否包含AND永假条件
condition-and-alway-true-allow: #检查查询条件(WHERE/HAVING子句)中是否包含AND永真条件
condition-double-const-allow: #查询条件中是否允许连续两个常量运算表达式
condition-like-true-allow: #检查查询条件(WHERE/HAVING子句)中是否包含LIKE永真条件
condition-op-bitwse-allow: #查询条件中是否允许有"&"、"~"、"|"、"^"运算符。
condition-op-xor-allow: #查询条件中是否允许有XOR条件。XOR不常用,很难判断永真或者永假,缺省不允许。
const-arithmetic-allow: #拦截常量运算的条件,比如说WHERE FID = 3 - 1,其中"3 - 1"是常量运算表达式。
limit-zero-allow: #是否允许limit 0这样的语句
select-limit: #配置最大返回行数,如果select语句没有指定最大返回行数,会自动修改select添加返回限制
#DML
insert-allow: #是否允许执行insert语句
insert-values-check-size: #检查insert values的大小?
complete-insert-values-check: #完整的检查insert的values
intersect-allow: #是否允许SELECT * FROM A INTERSECT SELECT * FROM B这样的语句
delete-allow: #是否允许执行delete语句
delete-where-alway-true-check: #检查DELETE语句的WHERE子句是否是一个永真条件
delete-where-none-check: #检查DELETE语句是否无where条件,这是有风险的,但不是SQL注入类型的风险
update-allow: #是否允许执行update语句
update-check-handler: #更新检查处理器?
update-where-alay-true-check: #检查UPDATE语句的WHERE子句是否是一个永真条件
update-where-none-check: #检查UPDATE语句是否无where条件,这是有风险的,但不是SQL注入类型的风险
#DDL
none-base-statement-allow: #是否允许非以上基本语句的其他语句,缺省关闭,通过这个选项就能够屏蔽DDL。
alter-table-allow: #是否允许执行Alter Table语句
create-table-allow: #是否允许执行create table语句
truncate-allow: #是否允许执行truncate语句
rename-table-allow: #是否允许rename table语句
drop-table-allow: #是否允许自行 drop table
#DCL
show-allow: #是否允许使用show语法
call-allow: #是否允许通过jdbc的call语法调用存储过程
commit-allow: #是否允许执行commit操作
rollback-allow: #是否允许回滚
use-allow: #是否允许使用use语法
##其他
# DB设置
set-allow: #是否允许使用SET语法
replace-allow: #是否允许执行REPLACE语句
read-only-tables: #指定的表只读,不能够在SELECT INTO、DELETE、UPDATE、INSERT、MERGE中作为"被修改表"出现
must-parameterized: #是否必须参数化,如果为True,则不允许类似WHERE ID = 1这种不参数化的SQL
multi-statement-allow: #是否允许一次执行多条语句,缺省关闭
lock-table-allow: #是否允许锁表
strict-syntax-check: #是否进行严格的语法检测,Druid SQL Parser在某些场景不能覆盖所有的SQL语法,出现解析SQL出错,可以临时把这个选项设置为false,同时把SQL反馈给Druid的开发者。
describe-allow: #是否允许执行mysql的describe语句,缺省打开
merge-allow: #是否允许执行MERGE语句,这个只在Oracle中有用
comment-allow: #是否允许语句中存在注释,Oracle的用户不用担心,Wall能够识别hints和注释的区别
# 黑名单配置
deny-functions: #方法 黑名单
deny-objects: #对象 黑名单
deny-schemas: #Schema 黑名单
deny-tables: #表格 黑名单
deny-variants: #变量 黑名单
# 白名单
permit-functions: #方法 白名单
permit-schemas: #schemas 白名单
permit-tables: #表格 白名单
permit-variants: #变量 白名单
function-check: #检测是否使用了禁用的函数
object-check: #检测是否使用了“禁用对对象
schema-check: #检测是否使用了禁用的Schema
table-check: #检测是否使用了禁用的表
variant-check: #检测是否使用了禁用的变量
#JDBC设置
metadata-allow: #是否允许是否允许调用Connection.getMetadata方法,这个方法调用会暴露数据库的表信息
wrap-allow: #是否允许调用Connection/Statement/ResultSet的isWrapFor和unwrap方法,这两个方法调用,使得有办法拿到原生驱动的对象,绕过WallFilter的检测直接执行SQL
#不知道干嘛用的设置
dir: #定配置装载的目录
start-transaction-allow: #是否允许使用start transaction?
inited: #邀请?
block-allow: #是否允许阻塞
hint-allow: #是否允许提示?
case-condition-const-allow: #
do-privileged-allow: #
tenant-column: #占用列?
tenant-table-pattern: #占用表方式?
# web应用
WebStatFilter用于采集web-jdbc关联监控的数据,可以采集执行时间、并发、JDBC执行数、事务、读取行数、更新行数等信息。
# 监控效果
web应用可以监控整个服务的执行信息

URI监控 能够监控单个url的执行信息

seesion监控 能够监控单个session对应的执行信息。

spring监控 Spring和Jdbc的关联监控,可以监控方法级的执行信息

# 监控配置
配置信息
spring:
datasource:
druid:
#统计web请求
web-stat-filter:
enabled: true
url-pattern: /* #监控URL
exclusions: /druid/*,*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico #对这些请求放行
principal-cookie-name: #cookie名称?
principal-session-name: #session名称?
profile-enable: true #监控URL 调用的SQL列表
session-stat-enable: true #统计session
session-stat-max-count: 1000 #统计最大session数
你可以配置principalSessionName,使得druid能够知道当前的session的用户是谁 修改为你user信息保存在session中的sessionName。 如果你的user信息保存在cookie中,你可以配置principalCookieName,使得druid知道当前的user是谁
# spring监控
java
@Bean
public DruidStatInterceptor druidStatInterceptor() {
DruidStatInterceptor dsInterceptor = new DruidStatInterceptor();
return dsInterceptor;
}
@Bean
@Scope("prototype")
public JdkRegexpMethodPointcut druidStatPointcut() {
JdkRegexpMethodPointcut pointcut = new JdkRegexpMethodPointcut();
pointcut.setPatterns("com.mediway.hos.*.service.*","com.mediway.hos.*.mapper.*");
return pointcut;
}
@Bean
public DefaultPointcutAdvisor druidStatAdvisor(DruidStatInterceptor druidStatInterceptor, JdkRegexpMethodPointcut druidStatPointcut) {
DefaultPointcutAdvisor defaultPointAdvisor = new DefaultPointcutAdvisor();
defaultPointAdvisor.setPointcut(druidStatPointcut);
defaultPointAdvisor.setAdvice(druidStatInterceptor);
return defaultPointAdvisor;
}
# LogFilter
Druid内置提供了四种LogFilter(Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter),用于输出JDBC执行的日志。
在HOS平台中已使用mybatis的SQL打印配置,因此不再使用Druid输出SQL日志。
# ConfigFilter
ConfigFilter的作用包括:
- 从配置文件中读取配置
- 从远程http文件中读取配置
- 为数据库密码提供加密功能
# 配置文件从本地文件系统中读取
spring:
datasource:
druid:
filters: config
connection-properties: config.file=file:///home/admin/druid-pool.properties
# 配置文件从远程http服务器中读取
spring:
datasource:
druid:
filters: config
connection-properties: config.file=http://127.0.0.1/druid-pool.properties
# 数据库密码加密
由于HOS已经提供对整个配置文件任一配置项脱敏的组件(配置文件脱敏组件),而该功能只能对数据库的密码加密,故在HOS平台中不采用该方案。
# EncodingConvertFilter
由于历史原因,一些数据库保存数据的时候使用了错误编码,需要做编码转换。
spring:
datasource:
druid:
filters: encoding
connection-properties: clientEncoding=UTF-8;serverEncoding=ISO-8859-1
通过filters属性配置了Filters属性,encoding是EncodingConvertFilter的别名。然后通过connectionProperties来配置客户端编码和服务器端编码。
# 全量配置
yaml
spring:
datasource:
druid:
url:
username:
password:
access-to-underlying-connection-allowed: false #允许访问底层连接
active-connection-stack-trace: #活跃连接堆跟踪
active-connections: #活跃连接列表
aop-patterns: #AOP模式
async-close-connection-enable: false #启用异步关闭连接
async-init: false #异步初始化
break-after-acquire-failure: false #失败后跳过
clear-filters-enable: false #启动清除过滤器
connect-properties: #连接配置
connection-error-retry-attempts: 1 #连接出错尝试几次重新连接
connection-init-sqls: #连接初始化语句
connection-properties: #连接属性
create-scheduler: #创建程序
db-type: #DB类型
default-auto-commit: false #默认自动提交
default-catalog: #默认目录
default-read-only: false #默认只读
default-transaction-isolation: 1 #默认事务隔离
destroy-scheduler: #销毁程序
driver: #驱动类
driver-class-name: #驱动类名
dup-close-log-enable: true #启用DUP关闭日志
enable: true #启动连接池
exception-sorter:
exception-sorter-class-name:
fail-fast: true #快速失败?
filter-class-names: #过滤器类名称
#过滤器配置
filter:
config:
enabled: false #启用Enable ConfigFilter.
encoding:
enabled: false #启用EncodingConvertFilter
#commons-log配置
commons-log:
connection-close-after-log-enabled:
connection-commit-after-log-enabled:
connection-connect-after-log-enabled:
connection-connect-before-log-enabled:
connection-log-enabled:
connection-log-error-enabled:
connection-logger-name:
connection-rollback-after-log-enabled:
data-source-log-enabled:
data-source-logger-name:
enabled:
result-set-close-after-log-enabled:
result-set-log-enabled:
result-set-log-error-enabled:
result-set-logger-name:
result-set-next-after-log-enabled:
result-set-open-after-log-enabled:
statement-close-after-log-enabled:
statement-create-after-log-enabled:
statement-executable-sql-log-enable:
statement-execute-after-log-enabled:
statement-execute-batch-after-log-enabled:
statement-execute-query-after-log-enabled:
statement-execute-update-after-log-enabled:
statement-log-enabled:
statement-log-error-enabled:
statement-logger-name:
statement-parameter-clear-log-enable:
statement-parameter-set-log-enabled:
statement-prepare-after-log-enabled:
statement-prepare-call-after-log-enabled:
statement-sql-format-option:
desensitize:
parameterized:
pretty-format:
upp-case:
statement-sql-pretty-format:
#LOG4J配置
log4j:
connection-close-after-log-enabled:
connection-commit-after-log-enabled:
connection-connect-after-log-enabled:
connection-connect-before-log-enabled:
connection-log-enabled:
connection-log-error-enabled:
connection-logger-name:
connection-rollback-after-log-enabled:
data-source-log-enabled:
data-source-logger-name:
enabled:
result-set-close-after-log-enabled:
result-set-log-enabled:
result-set-log-error-enabled:
result-set-logger-name:
result-set-next-after-log-enabled:
result-set-open-after-log-enabled:
statement-close-after-log-enabled:
statement-create-after-log-enabled:
statement-executable-sql-log-enable:
statement-execute-after-log-enabled:
statement-execute-batch-after-log-enabled:
statement-execute-query-after-log-enabled:
statement-execute-update-after-log-enabled:
statement-log-enabled:
statement-log-error-enabled:
statement-logger-name:
statement-parameter-clear-log-enable:
statement-parameter-set-log-enabled:
statement-prepare-after-log-enabled:
statement-prepare-call-after-log-enabled:
statement-sql-format-option:
desensitize:
parameterized:
pretty-format:
upp-case:
statement-sql-pretty-format:
#LOG4J2配置
log4j2:
connection-close-after-log-enabled:
connection-commit-after-log-enabled:
connection-connect-after-log-enabled:
connection-connect-before-log-enabled:
connection-log-enabled:
connection-log-error-enabled:
connection-logger-name:
connection-rollback-after-log-enabled:
data-source-log-enabled:
data-source-logger-name:
enabled:
result-set-close-after-log-enabled:
result-set-log-enabled:
result-set-log-error-enabled:
result-set-logger-name:
result-set-next-after-log-enabled:
result-set-open-after-log-enabled:
statement-close-after-log-enabled:
statement-create-after-log-enabled:
statement-executable-sql-log-enable:
statement-execute-after-log-enabled:
statement-execute-batch-after-log-enabled:
statement-execute-query-after-log-enabled:
statement-execute-update-after-log-enabled:
statement-log-enabled:
statement-log-error-enabled:
statement-logger-name:
statement-parameter-clear-log-enable:
statement-parameter-set-log-enabled:
statement-prepare-after-log-enabled:
statement-prepare-call-after-log-enabled:
statement-sql-format-option:
desensitize:
parameterized:
pretty-format:
upp-case:
statement-sql-pretty-format:
#slf4j配置
slf4j:
connection-close-after-log-enabled:
connection-commit-after-log-enabled:
connection-connect-after-log-enabled:
connection-connect-before-log-enabled:
connection-log-enabled:
connection-log-error-enabled:
connection-logger-name:
connection-rollback-after-log-enabled:
data-source-log-enabled:
data-source-logger-name:
enabled:
result-set-close-after-log-enabled:
result-set-log-enabled:
result-set-log-error-enabled:
result-set-logger-name:
result-set-next-after-log-enabled:
result-set-open-after-log-enabled:
statement-close-after-log-enabled:
statement-create-after-log-enabled:
statement-executable-sql-log-enable:
statement-execute-after-log-enabled:
statement-execute-batch-after-log-enabled:
statement-execute-query-after-log-enabled:
statement-execute-update-after-log-enabled:
statement-log-enabled:
statement-log-error-enabled:
statement-logger-name:
statement-parameter-clear-log-enable:
statement-parameter-set-log-enabled:
statement-prepare-after-log-enabled:
statement-prepare-call-after-log-enabled:
statement-sql-format-option:
desensitize:
parameterized:
pretty-format:
upp-case:
statement-sql-pretty-format:
#stat过滤器:统计监控信息
stat:
connection-stack-trace-enable: true #启动连接堆跟踪
db-type: mysql #数据库类型
enabled: true #启用
log-slow-sql: true #记录慢SQL
merge-sql: true #合并相同查询语句(参数不同)
slow-sql-millis: 10000 #log-slow-sql为true,多久(ms)才表示为慢SQL
#防火墙配置
wall:
config:
##语句防火墙
#DQL
selelct-allow: #是否允许执行select语句
select-all-column-allow: #是否允许执行SELECT * FROM T这样的语句。如果设置为false,不允许执行select * from t,但select * from (select id, name from t) a。这个选项是防御程序通过调用select *获得数据表的结构信息。
select-except-check: #检测SELECT EXCEPT
select-intersect-check: #检测SELECT INTERSECT
select-minus-check: #检测SELECT MINUS
select-union-check: #检测SELECT UNION
select-into-allow: #是否允许执行 select into 语句
minus-allow: #是否允许SELECT * FROM A MINUS SELECT * FROM B这样的语句
select-into-outfile-allow: #SELECT ... INTO OUTFILE 是否允许,这个是mysql注入攻击的常见手段,缺省是禁止的
select-where-alway-true-check: #检查SELECT语句的WHERE子句是否是一个永真条件
select-having-alway-true-check: #检查SELECT语句的HAVING子句是否是一个永真条件
condition-and-alway-false-allow: #检查查询条件(WHERE/HAVING子句)中是否包含AND永假条件
condition-and-alway-true-allow: #检查查询条件(WHERE/HAVING子句)中是否包含AND永真条件
condition-double-const-allow: #查询条件中是否允许连续两个常量运算表达式
condition-like-true-allow: #检查查询条件(WHERE/HAVING子句)中是否包含LIKE永真条件
condition-op-bitwse-allow: #查询条件中是否允许有"&"、"~"、"|"、"^"运算符。
condition-op-xor-allow: #查询条件中是否允许有XOR条件。XOR不常用,很难判断永真或者永假,缺省不允许。
const-arithmetic-allow: #拦截常量运算的条件,比如说WHERE FID = 3 - 1,其中"3 - 1"是常量运算表达式。
limit-zero-allow: #是否允许limit 0这样的语句
select-limit: #配置最大返回行数,如果select语句没有指定最大返回行数,会自动修改select添加返回限制
#DML
insert-allow: #是否允许执行insert语句
insert-values-check-size: #检查insert values的大小?
complete-insert-values-check: #完整的检查insert的values
intersect-allow: #是否允许SELECT * FROM A INTERSECT SELECT * FROM B这样的语句
delete-allow: #是否允许执行delete语句
delete-where-alway-true-check: #检查DELETE语句的WHERE子句是否是一个永真条件
delete-where-none-check: #检查DELETE语句是否无where条件,这是有风险的,但不是SQL注入类型的风险
update-allow: #是否允许执行update语句
update-check-handler: #更新检查处理器?
update-where-alay-true-check: #检查UPDATE语句的WHERE子句是否是一个永真条件
update-where-none-check: #检查UPDATE语句是否无where条件,这是有风险的,但不是SQL注入类型的风险
#DDL
none-base-statement-allow: #是否允许非以上基本语句的其他语句,缺省关闭,通过这个选项就能够屏蔽DDL。
alter-table-allow: #是否允许执行Alter Table语句
create-table-allow: #是否允许执行create table语句
truncate-allow: #是否允许执行truncate语句
rename-table-allow: #是否允许rename table语句
drop-table-allow: #是否允许自行 drop table
#DCL
show-allow: #是否允许使用show语法
call-allow: #是否允许通过jdbc的call语法调用存储过程
commit-allow: #是否允许执行commit操作
rollback-allow: #是否允许回滚
use-allow: #是否允许使用use语法
##其他
# DB设置
set-allow: #是否允许使用SET语法
replace-allow: #是否允许执行REPLACE语句
read-only-tables: #指定的表只读,不能够在SELECT INTO、DELETE、UPDATE、INSERT、MERGE中作为"被修改表"出现
must-parameterized: #是否必须参数化,如果为True,则不允许类似WHERE ID = 1这种不参数化的SQL
multi-statement-allow: #是否允许一次执行多条语句,缺省关闭
lock-table-allow: #是否允许锁表
strict-syntax-check: #是否进行严格的语法检测,Druid SQL Parser在某些场景不能覆盖所有的SQL语法,出现解析SQL出错,可以临时把这个选项设置为false,同时把SQL反馈给Druid的开发者。
describe-allow: #是否允许执行mysql的describe语句,缺省打开
merge-allow: #是否允许执行MERGE语句,这个只在Oracle中有用
comment-allow: #是否允许语句中存在注释,Oracle的用户不用担心,Wall能够识别hints和注释的区别
# 黑名单
deny-functions: #方法 黑名单
deny-objects: #对象 黑名单
deny-schemas: #Schema 黑名单
deny-tables: #表格 黑名单
deny-variants: #变量 黑名单
# 白名单
permit-functions: #方法 白名单
permit-schemas: #schemas 白名单
permit-tables: #表格 白名单
permit-variants: #变量 白名单
function-check: #检测是否使用了禁用的函数
object-check: #检测是否使用了“禁用对对象
schema-check: #检测是否使用了禁用的Schema
table-check: #检测是否使用了禁用的表
variant-check: #检测是否使用了禁用的变量
#JDBC设置
metadata-allow: #是否允许是否允许调用Connection.getMetadata方法,这个方法调用会暴露数据库的表信息
wrap-allow: #是否允许调用Connection/Statement/ResultSet的isWrapFor和unwrap方法,这两个方法调用,使得有办法拿到原生驱动的对象,绕过WallFilter的检测直接执行SQL
#不知道干嘛用的设置
dir: #定配置装载的目录
start-transaction-allow: #是否允许使用start transaction?
inited: #邀请?
block-allow: #是否允许阻塞
hint-allow: #是否允许提示?
case-condition-const-allow: #
do-privileged-allow: #
tenant-column: #占用列?
tenant-table-pattern: #占用表方式?
db-type: #db类型
enabled: #启用
log-violation: #对被认为是攻击的SQL进行LOG.error输出
provider-white-list: #白名单?
tenant-column: #占用列?
throw-exception: #对被认为是攻击的SQL抛出SQLExcepton
filters: #过滤器名称?
init-global-variants: false #初始化全局变量?
init-variants: false #初始化变量?
initial-size: 10 #初始化时建立物理连接的个数
keep-alive: #连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作
kill-when-socket-read-timeout: true #socket连接超时时kill
log-abandoned: false #记录丢失?
log-different-thread: #记录不同的线程?
login-timeout: #连接超时?
max-active: 50 #最大连接池数量
max-create-task-count: 10 #最大创建任务数
max-evictable-idle-time-millis: #连接保持空闲而不被驱逐的最大时间
#max-idle: #已弃用
max-open-prepared-statements: 100 #最大打开的prepared-statements
max-pool-prepared-statement-per-connection-size: 100 #?
max-wait: #获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
max-wait-thread-count: #最大的线程等待数
min-evictable-idle-time-millis: #连接保持空闲而不被驱逐的最小时间
min-idle: 5 #最小连接池数量
name:
not-full-timeout-retry-count: #
num-tests-per-eviction-run: #
object-name:
m-bean-server:
on-fatal-error-max-active: #
oracle: #
password-callback: #
phy-timeout-millis: #物理超时
pool-prepared-statements: #prepared-statements线程池?
pooling-connection-info: #池连接信息?
proxy-filters: #代理过滤器?
query-timeout: #查询超时时间
remove-abandoned: #移除被遗弃的?
remove-abandoned-timeout: #移除超时时间?
remove-abandoned-timeout-millis: #移除超时时间毫秒?
reset-stat-enable: false #启用重置统计信息
share-prepared-statements: #分布式prepared-statements?
sql-stat-map: #
stat-data: #
stat-data-for-m-bean: #
stat-logger: #
stat-view-servlet:
allow: #白名单
deny: #黑名单
enabled: true
login-password: #登录密码
login-username: #登录用户
reset-enable: #启用重置统计信息
url-pattern: #访问路径
test-on-borrow: #申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能
test-on-return: #归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
test-while-idle: #建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
time-between-connect-error-millis: #连接错误之间的时间
time-between-eviction-runs-millis: #有两个含义:1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明
time-between-log-stats-millis: #统计日志之间的时间
transaction-query-timeout: #事务查询超时时间
transaction-threshold-millis: #事务使用时长?
use-global-data-source-stat: #使用全局数据源统计?
use-local-session-state: #使用本地服务统计?
use-oracle-implicit-cache: #使用oracle 内置缓存?
use-unfair-lock: #使用不公平锁?
user-callback: #用户回调?
valid-connection-checker: #连接的有效检查类
valid-connection-checker-class-name: #连接的有效检查类名
validation-query: #用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
validation-query-timeout: #单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法
wall-stat-map: #
#统计web请求
web-stat-filter:
enabled: true
exclusions: *.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/* #排除URL
principal-cookie-name: #cookie名称?
principal-session-name: #session名称?
profile-enable: true #监控URL 调用的SQL列表
session-stat-enable: true #统计session
session-stat-max-count: 1000 #统计最大session数
url-pattern: /* #监控URL